Continuations, Goto et iterateurs.
Le goto n'existe pas en Ruby, Matz y serait opposé. Mais il est possible d'en implémenter un, cela n'a guère d'intérêt sinon de donner un exemple pour expliquer les continuations et la notion d'itérateur interne et externe.
Contenu.
1 Le module Goto.1.1 Le code.
1.2 Explications.
1.3 Liens.
2 Itérateurs internes et externes.
2.1 Concepts.
2.2 Iterateurs externes.
2.3 Les classes Generator et Enumerator.
2.4 Un itérateur sur un array.
2.5 Comparaisons & benchmarks.
2.6 Conclusions sur les itérateurs.
3 Conclusions.
4 Un dernier mot.
1 Le module Goto.
1.1 Le code.
Ce petit module utilise Kernel#callcc pour garder le contexte d'exécution et Continuation#call pour revenir à ce contexte à la fin du block de callcc.
module Goto
def label
ret = nil
callcc { |cont| ret = cont }
# <======= ICI
ret
end
def goto(x)
x.call # =======>
end
end
Son utilisation apparaîtra mieux dans ce code de test :
#!/usr/bin/env ruby
require 'goto.rb'
include Goto
ary = ['to', 'be', 'or', 'not', 'to', 'be']
ind = 0
str = ''
again = label
if ind < ary.size
str << "#{ary[ind]} "
ind += 1
goto again
end
puts str
Cet exemple est encore plus simpliste que celui donné dans le Pragmatic programmer's Guide
1.2 Explications.
callcc garde l'état du process dans un objet de classe continuation
et l'appel de la methode call de cet objet restitue ce contexte et continue
le process à l'endroit situé après l'appel de callcc.
On peut aussi utiliser call de le continuation courante dans le block
fourni à callcc.
Le code de test est un exemple de ce qu'il faut éviter de faire, pas seulement pace que ça commence à ressembler à du Cobol, mais aussi parce que les continuations sont très gourmandes en ressources CPU et mémoire.
Il y a bien des façons plus simples d'écrire ce code en Ruby. Par exemple :
ary = ['to', 'be', 'or', 'not', 'to', 'be']
puts ary.join(' ')
Pour ceux qui connaissent le C, callcc/call a été comparé à
setjump()/longjump() mais c'est plus complexe.
setjump()/longjump() ne fait que guère que se repositionner
dans la pile plutôt à la manière de catch/throw.
callcc/call permet de se positionner à un endroit qui n'est
plus sur la pile et cela oblige callcc à sauvegarder cette pile,
et c'est coûteux.
Je pense qu'il y a très peu de cas dans lesquels l'utilisation de
continuations se justifie dans une application pour laquelle
la performance est importante.
Les continuations sont parfois utilisé dans des
applications web pour conserver le contexte avant d'envoyer une
réponse. Dans ce cas, il n'y a qu'un appel de call et callcc par requête
et cela peut se justifier si cela apporte des facilités à l'application.
D'autres exemples d'application dans cet
article sur l'utilisation des continuations [Pdf].
1.3 Liens.
Quelques liens pour continuer :
[En]Continuation sur http://wiki.rubygarden.org/.
[En]Continuation explanation sur http://wiki.rubygarden.org/.
[Fr]Jouons avec les continuations avec des exemples en Scheme et Ruby.
[En]Continuations and Ruby.
[En]Continuations and exceptions.
[En]Continuations and the web, une explication simple de l'utilité
des continuations.
Bonne continuation...
2 Itérateurs internes et externes.
2.1 Concepts.
Une itération, en Ruby, peut s'effecuer de plusieurs manières
suivant les besoins, voir pour cela les possibilités du
module Enumerable.
Une manière classique est d'utiliser la methode each sur laquelle
sont basées les autres methodes du module Enumerable.
collection.each do |element|
# on utilise l'element de la collection
end
Il s'agit d'un iterateur interne, le block dans lequel on utilise l'element de la collection est appelé par yield de la methode each.
D'autres langages utilisent des Iterateurs externes que l'on peut également implementer en Ruby :
iter = Generator.new(collection)
while iter.next?
element = iter.next
# on utilise l'element de la collection
end
Ici, c'est la methode next de l'instance de l'iterator qui est appelée.
Je trouve l'itérateur interne plus élégant et il convient dans la très grande majorité des cas. Il y a cependant des cas dans lesquels il ne peut convenir, lorsque, par exemple, on veut iterer en parallèle dans plusieurs collections.
La bibliothèque standard de Ruby contient la classe Generator qui convertit un Iterateur interne en un iterateur externe. Le même source (generator.rb) contient aussi la class SyncEnumerator dont la methode each 'yielde' un array des elements de même rang des objets enumerables donnés en argument de sa fonction new.
2.2 Iterateurs externes.
Il n'y a pas grand chose à ajouter sur les itérateurs internes, ils sont très bien et conviennent dans la très grande majorité des cas.
Cependant et notamment pour iterer en même temps et de manière
indépendante dans plusieurs collections d'objets, il est parfois
nécessaire d'utiliser un iterateur externe.
Je connais 3 manières pour obtenir un Iterateur externe :
- Ecrire une classe dont les methodes transforment un objet enumerable en array par la methode to_a de cet objet et itèrent sur cet array. Cette classe est simple à écrire et le source sera donné plus bas,
- Utiliser la classe Generator ou une autre technique basée sur les continuations,
-
Utiliser un thread separé pour faire l'itération, ou pourquoi pas
un process voire un autre ordinateur.
Nous étudierons cette possibilité un autre jour.
Il y aurait encore d'autres possibilités, mais elles me paraissent trop tordues pour en faire état ici.
Les 3 manières ont leurs avantages et leurs inconvénients. Commençons par étudier l'utilisation de la classe Generator.
2.3 Les classes Generator et Enumerator.
Pour savoir ce que contient la classe Generator,
on peut se référer à son source qui est, à mon avis, assez sophistiqué.
Il fait appel aux continuations
Voici une version simple d'un iterateur faisant appel aux continuations,
nous l'appellerons
Enumerator.
Il demande aussi que l'objet ait une methode size (qui n'est pas
dans le module Enumerable, mais que beaucoup d'Enumerables doivent
implémenter).
class Enumerator
# the enumerable object must respond to size
def initialize(enum)
@enum = enum
@num = 0
end
def next?; @num < @enum.size; end
def end?; ! next?; end
def next
raise(EOFError, "No more entry available.") if end?
callcc do |cont|
@return = cont
@do ? @do.call : do_next
end
return @item
end
private
def do_next
@enum.each do |item|
callcc do |cont|
@do = cont
@num += 1
@item = item
@return.call
end
end
end
end
Et son code de test :
#!/usr/bin/env ruby
require 'enumerator.rb'
ary = [ 'to', 'be', 'or', 'not', 'to', 'be' ]
iter = Enumerator.new(ary)
str = ''
while iter.next?
str << "#{iter.next} "
end
str[-1] = ?. unless str.empty?
puts str
Ce code de test est vraiment minimal ! Il ne suffit pas pour assurer que cela marche, il assure juste que ça semble marcher.
Ce qui nous donne le résultat suivant :
to be or not to be.
2.4 Un itérateur sur un array.
Nous avons comme alternative la possibilité d'itérer de manière
externe sur un objet énumérable par sa methode
to_a qui
produit un array à partir de cet objet.
Il est ensuite très simple de construire un itérateur externe sur
un array car on peut accéder directement à ses éléments par leur
index que l'on peut incrémenter.
Voyons son code :
class Iterator
def initialize(enum)
@ary = enum.kind_of?(Array) ? enum : enum.to_a
@index = 0
end
def next?; @index < @ary.size ; end
def end?; ! next?; end
def next
raise(EOFError, "No more entry available.") unless next?
ret = @ary[@index]
@index += 1
ret
end
def rewind; @index = 0; end
end
Trivial, n'est-ce pas !
Le code de test est le même que celui au-dessus et ne vaut toujours pas
grand chose mais il produit le même résultat.
L'iterateur ne conserve, comme variables d'instance, que des références à
l'array et à l'index courant, le strict minimum, alors que les classes
Generator et Enumerator conservent tout le contexte d'execution qui
est sauve et restauré à chaque appel.
Il a par contre le désavantage d'avoir à créer préalablement un array
à partir de l'objet sur lequel il doit iterer lorsque cet objet n'est
pas une espèce d'array.
2.5 Comparaisons & benchmarks.
On peut comparer les différentes solutions selon un certain nombre de critères, je ne m'attacherai qu'aux critères de performance qui sont plus mesurables que les critères d'élégance.
Pour cela j'ai fait un petit script qui mesure les temps d'exécution
sur des hashes qui fournissent un exemple de classe sur laquelle on
ne peut directement construire un itérteur externe.
Le script faisant les benchmarks n'est pas présenté ici, mais vous pouvez le trouver dans ce tarball comprenant les exemples.
L'image suivante montre le temp CPU utilisé pour le parcours complet
d'un hash en fonction de sa taille en utilisant les classes suivantes
d'itérateurs externes:
. Generator : l'itérateur de la bibliothèque standard,
. Enumerator : une version simple (mais peut-être buggée)
d'itérateur utilisant les continuations,
. Iterator : un itérateur qui, à partir de l'objet enumerable,
crée préalablement un array sur lequel il va itérer.

L'axe des abscisses donne le nombre d'éléments dans le hash et celui
des ordonnées donne le temps CPU en dixièmes de secondes.
Pour des tailles différentes de hashes, les courbes ont la même forme et le temps est grossièrement proportionnel à la taille, on ne le voit pas très bien pour Iterator qui fait du rase-motte, cela se remarque mieux en utilisant une échelle logarithmique pour les 2 axes :
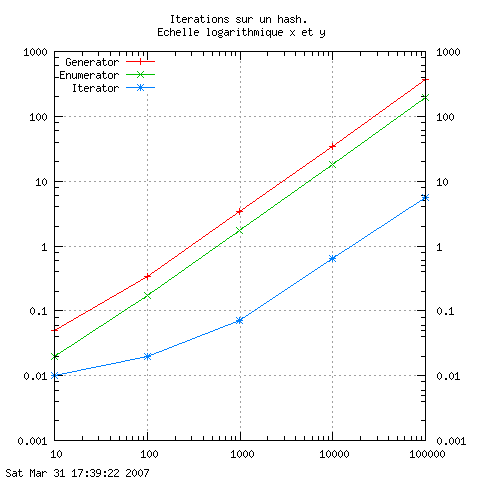
On peut estimer qu'en gros, Enumerator est 2 fois plus rapide que Generator et Iterator 40 à 50 fois plus rapide que Generator.
Les elements des hashes (clés et valeurs) ont été choisis de petite taille
(objets de la classe Symbol) de façon à ne pas polluer les résultats
par des copies d'objets et parce que cela correspondait
au cas que j'étudiais.
Notons que cela favorise Iterator qui doit copier préalablement le
hash.
Pour l'occupation mémoire, je n'ai pas de tests formels, mais l'observation me laisse penser que pour les tailles étudiées (1..100000), elle est sensiblement la même avec un avantage pour Iterator surtout pour les petits et moyens hashes.
2.6 Conclusions sur les itérateurs.
Je pense qu'il est préférable d'utiliser des itérateurs internes qui suffisent dans une très grande majorité de cas et que si doit utiliser un iterateur externe, il est préférable d'éviter de le baser sur des continuations.
3 Conclusions.
Utilisons les continuations avec parcimonie et à bon escient.
Elles sont très bien pour conserver facilement l'état d'un processus
mais cela a un coût, car est conservé en général bien plus que ce qui est
nécessaire pour définir l'etat et y revenir.
